Core Overview
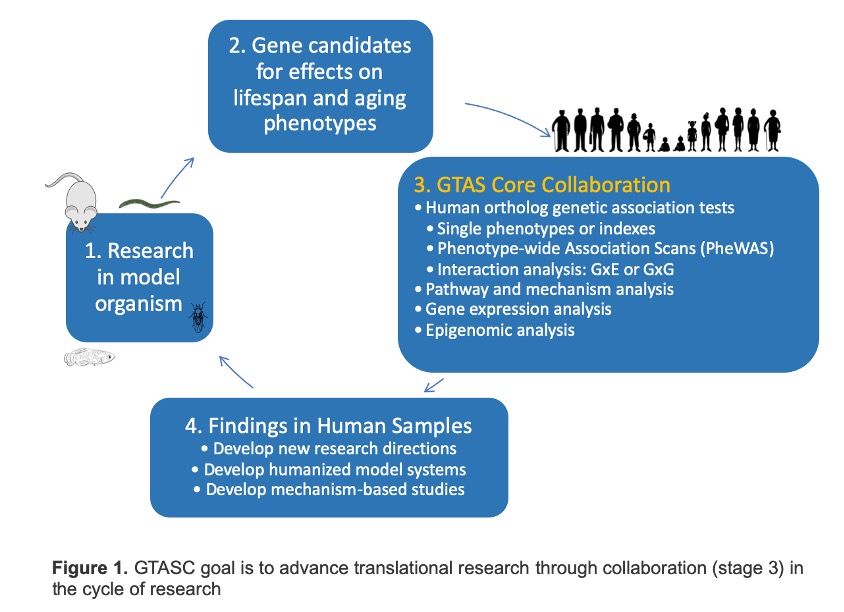
The Genomic Translation Across Species Core (GTASC) Core, led by Eileen Crimmins and Em Arpawong at USC, will overcome a historical barrier of connecting geroscience research in model systems to human health and aging. The core will provide researchers utilizing model-organisms (yeast, worms, flies, fish, and mice) the ability to interrogate rich resources of human genomic, methylation, and expression data from large-scale, longitudinal, ethnically diverse, population-based datasets of aging. Evaluating hypotheses that are driven by findings from model-organisms in deeply phenotyped human data will provide important results in the context of human aging and facilitate innovative research directions across models.